Hjemmeside » Coding » Sådan oprettes en RSS Reader App i JavaScript
Sådan oprettes en RSS Reader App i JavaScript
RSS (Really Simple Syndication) er et standardiseret format, der bruges af udgivere online til syndikere deres indhold til andre hjemmesider og tjenester. en RSS-dokument, også kendt som a foder, er en XML-dokument bærer det indhold, som en udgiver ønsker at distribuere.
RSS-feeds er tilgængelige på næsten alle online nyhedswebsteder og blogs for deres læsere til Hold dig ajour med deres indhold. De kan også findes på ikke-tekstbaserede hjemmesider f.eks. YouTube, hvor du kan bruge feedet fra en YouTube-kanal til at være informeret om de nyeste videoer.
Programmer, der får adgang til disse feeds, og læser og viser deres indhold kaldes RSS læsere. Du kan oprette et simpelt RSS-læserprogram i JavaScript. I denne vejledning ser vi hvordan.
Struktur af et RSS-feed
Et RSS-feed har et rodelement hedder , svarende til tag fundet i HTML-dokumenter. Inde i tag, der er en element, slags lignende i HTML, det indeholder mange underelementer indeholdende det distribuerede indhold på hjemmesiden.
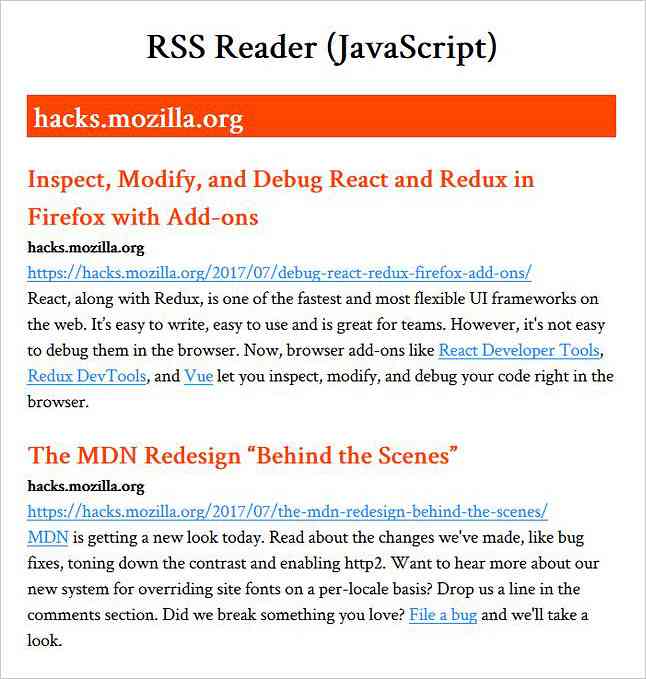
Et foder bærer normalt nogle grundlæggende oplysninger såsom titel, URL og beskrivelse af hjemmesiden og af individuelle opdaterede indlæg, artikler eller andet indhold af denne hjemmeside. Disse oplysninger findes i </code>, <code><link></code>, og <code><description></code> elementer.</p> <p>Når disse tags er <strong>direkte til stede indeni <code><channel></code></strong>, de har titel, URL og beskrivelse af hjemmesiden. Når de er <strong>nuværende inde <code><item></code></strong> at <strong>Indeholder oplysningerne om de opdaterede indlæg</strong>, de repræsenterer de samme oplysninger som før, men det for de enkelte indhold, som hver <code><item></code> repræsentere.</p> <p>Der er også nogle <strong>valgfrie elementer</strong> der kan være til stede i et RSS-feed, der giver supplerende oplysninger som billeder eller ophavsrettigheder på det distribuerede indhold. Du kan lære om dem i dette <strong>RSS 2.0 specifikation</strong> på cyber.harvard.edu.</p> <p>Her er et eksempel på hvordan <strong>RSS feed af en hjemmeside</strong> kan se ud:</p> <pre name="code"> <rss version="2.0"> <channel> <title>Hongkiat https://www.hongkiat.com/ Design Tips, Tutorial og Inspirationsen-osVisualiser ethvert CSS-formatark med CSS-statistikkerHar du nogensinde spekuleret på, hvor mange CSS-regler der findes i et stylesheet? Eller har du nogensinde ønsket at se ... 18/05/2017 https://www.hongkiat.com/blog/css-stylesheet-with-css-stats/ Amazon Echo Show - Den seneste Alexa-powered Smart DeviceAmazon er ikke fremmed for begrebet smart home-systemer med en integreret digital assistent. Trods alt 17/05/2017 https://www.hongkiat.com/blog/alexa-device-amazon-echo-show/
Henter feedet
Vi er nødt til hent foderet med vores RSS-læserapplikation. På et websted kan webadressen til et RSS-feed være fundet inde i tag ved hjælp af application / rss + xml type. For eksempel finder du følgende RSS feed link på Hongkiat.com.
Lad os først se hvordan få feed-URL'en til en hjemmeside ved hjælp af JavaScript.
hent (websiteUrl) .then ((res) => res.text () .hen ((htmlTxt) => var domParser = ny DOMParser () lad doc = domParser.parseFromString (htmlTxt, 'text / html') var feedUrl = doc.querySelector ('link [type = "application / rss + xml"]'). href))) .fang (() => console.error ('Fejl ved hentning af hjemmesiden'))
Det fetch () Metoden er en global metode der asynkront henter en ressource. Det tager URL'en til ressourcen som et argument (webadressen på hjemmesiden i vores kode). Det returnerer a Løfte objekt, så når metoden med held henter hjemmesiden (dvs. Løfte er opfyldt), den første funktion inde i derefter() udmelding håndterer det hentede svar (res i ovenstående kode).
Det hentede svar er da læses fuldt ud i en tekststreng bruger tekst() metode. Denne tekst repræsenterer HTML-tekst på vores hentede hjemmeside. Synes godt om fetch (), tekst() også returnerer a Løfte objekt. Så når det med succes opretter en svartekst fra responsstrømmen, derefter() vil håndtere denne svartekst (htmlText i ovenstående kode).
Når HTML-tekst på hjemmesiden er tilgængelig, bruger vi DOMParser API til analysere det i et DOM-dokument. DOMParser analyserer en XML / HTML-tekststreng i et DOM-dokument. Dens metode, parseFromString (), tager to argumenter: det tekst, der skal analyseres og indholdstype.
Derefter fra det oprettede DOM dokument, vi Find href værdien af den relevante tag bruger querySelector () metode for at få URL'en til feedet.
Parsering og visning af feedet
Når vi har fået webadressens feed-URL, skal vi hent og læs RSS-dokumentet fundet på den webadresse.
På samme måde som vi hentede og analyserede hjemmesiden, nu vi få og analysere XML-feedet i et DOM-dokument. For at opnå dette bruger vi 'Text / xml' indholdstype i parseFromString () metode.
I det analyserede dokument, vi vælg alle de elementer bruger querySelectorAll metode og loop gennem hver.